📈 Meus Trabalhos
Aqui destaco alguns dos projetos em que trabalhei ao longo da minha carreira profissional.
Disponho projetos econométricos, de classificação, regressão, clusterização, sistemas de recomendação, financeiros e em análise de dados.
💲 Econometria usando Python
Possuo um forte interesse em Econometria, principalmente por análises de Séries Temporais. Procuro empregar meus conhecimentos tanto em análises de séries univariadas, como o ARIMA e SARIMA, tanto quanto em séries multivariadas, como Vetores Autorregressivos (VAR) e Vetor de Correção de Erros (VEC).
Também procuro aprender e realizar projetos sobre Diferença em Diferenças, Impacto Causal, Causalidade de Granger e Propensity Score Matching. Por enquanto, aqui estão alguns dos meus projetos econométricos:
Como prever receitas com séries temporais em Python: um case da Olist
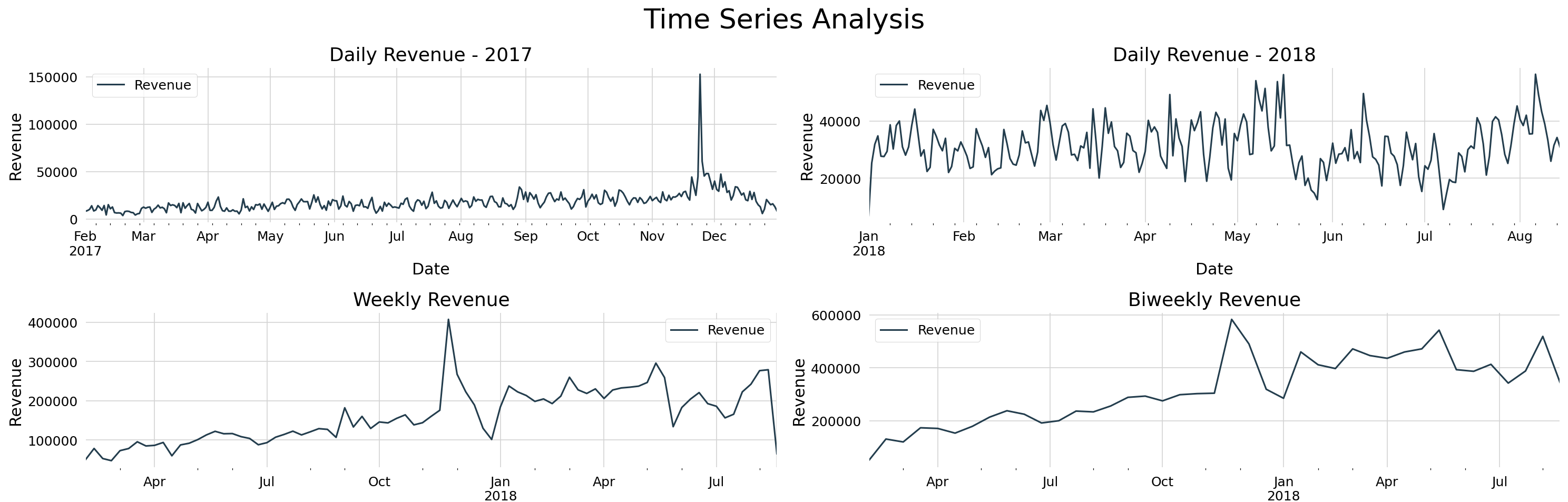
Problema de Negócio:
- A Olist encontrou um desafio na gestão das suas receitas devido a flutuações imprevistas nas vendas.
- Esperava-se vender mais nesta época do ano e fatores externos tornaram difícil para a empresa antecipar sua situação financeira.
Objetivos:
- Para resolver este problema, a utilização da metodologia de Séries Temporais univariada ARIMA é uma boa escolha para prever a receita das duas semanas seguintes.
- O objetivo principal é fornecer ao Olist modelos de previsão robustos, capazes de prever receitas para os próximos 14 dias.
Resultados:
- Em geral, os modelos produziram bons resultados com pequenos erros relativos.
- Os modelos Auto ARIMA e SARIMA se destacam por serem capazes de capturar os movimentos de oscilação dos dados no futuro.
- Munida de modelos de previsão e insights, a Olist pode prever receitas a fim de melhorar sua organização financeira, otimizar os recursos necessários e planejar investimentos para o futuro.
Ferramentas Utilizadas:
- Decomposição sazonal
- Augmented Dickey-Fuller (ADF) e Kwiatkowski-Phillips-Schmidt-Shin (KPSS)
- Função de Autocorrelação (ACF) e Função Parcial de Autocorrelação (PACF)
- Auto ARIMA, ARIMA e SARIMA
Veja o projeto completo no GitHub: GitHub
Leia sobre o processo do projeto no Medium (english): Medium
Projeto de elasticidade-preço da demanda

Contexto:
- Neste projeto fictício, exploro a elasticidade-preço da demanda por laptops e computadores.
- A análise emprega princípios fundamentais de elasticidade de preços para descobrir insights que possam orientar a tomada de decisões estratégicas
Objetivos:
- Escolher a categoria mais vendida da loja com mais vendas para aplicar a análise
- Entender como as variações de preços impactam a demanda do consumidor por produtos elásticos
Resultados:
- Análise Exploratória de Dados com vários insights
- Tabela com nomes dos produtos elásticos, a renda que geram atualmente, a variação de faturamento que podem gerar em valores monetários e em porcentagem
- O projeto demonstra a importância da modelagem econômica para empresas
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn
- Análise Exploratória de Dados
- Statsmodels
- Streamlit App
Estes projetos demonstram a minha experiência na aplicação de técnicas econométricas a problemas do mundo real, particularmente em previsão e análise de demanda.
📊 Projetos em Ciência de Dados
Introdução
Os seguintes projetos foram todos desenvolvidos em Python, seguindo a metodologia CRISP-DM (Cross-Industry Standard Process for Data Mining). Cada projeto tem como foco resolver um problema de negócio específico, utilizando técnicas de análise de dados e machine learning para obter insights.
Projetos de Classificação
Classificação de Clientes InStyle

Problema de Negócio:
- A loja de moda InStyle enfrenta desafios significativos em relação à experiência do cliente
- A equipe foi encarregada de treinar um algoritmo para classificar clientes entre "Satisfeito" e "Neutro ou Insatisfeito", prevendo clientes insatisfeitos para agir rapidamente e reverter o cenário
Objetivos:
- Gerar insights através dos dados
- Produzir informações visuais sobre a base de clientes
- Classificar e identificar clientes insatisfeitos através de um algoritmo de Machine Learning
Benefícios:
- Elevação da satisfação do cliente
- Fidelização e retenção
- Direcionamento eficiente de marketing
- Otimização de custos
- Otimização do fluxo de trabalho
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn
- Análise Exploratória de Dados
- Logistic Regression, RandomForestClassifier, XGBClassifier, LGBMClassifier
- Acurácia, Precisão, Recall, F1 Score, Classification Report e Matriz de Confusão
- Cross-Validation e Hyperparameter Tuning (RandomizerSearchCV)
Veja o projeto completo no GitHub: GitHub
Detecção de Doencas Cardiovasculares

Contexto de Negócio:
- Cardio Catch Disease é uma empresa de saúde especializada no diagnóstico de doenças cardiovasculares em estágios iniciais
- Seu modelo de negócio oferece esse diagnóstico precoce de doenças cardiovasculares por um determinado preço
- O problema é que a precisão do diagnóstico varia entre 55% e 65%, refletindo a sua complexidade e a limitada disponibilidade de médicos
Objetivos:
- Criar um modelo que melhore a precisão do diagnóstico de forma estável e eficiente para todos os clientes
- 1. Precisão do novo modelo
- 2. Qual a receita que o novo modelo retorna?
- 3. Quão confiáveis são os resultados da nova ferramenta?
Resultados alcançados:
- A precisão do modelo agora está em 75%
- Nova receita de $173.665.751,75
- O novo modelo gera um incremento de $68.665.751,75
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn
- Análise Exploratória de Dados
- Logistic Regression, ExtraTreesClassifier, RandomForestClassifier, LGBMClassifier
- Acurácia, Precisão, Recall, F1 Score, Classification Report e Matriz de Confusão
- Cross-Validation e Hyperparameter Tuning (RandomizerSearchCV)
Veja o projeto completo no GitHub: GitHub
Projetos de Regressão
Previsão de Vendas de Rossmann

Problema de Negócio:
- O CEO da rede de farmácias Rossmann planeja renovar as suas lojas pois a marca está passando por um rebranding, mas não sabe o quanto cada uma terá a disposição para investir nas reformas
Solução:
- Vários modelos de Machine Learning foram testados a fim de prever o faturamento das lojas para as seis semanas seguintes, com o objetivo de prever quanto dinheiro cada loja da Rossmann terá disponível para gastar em suas reformas
Resultados:
- Através de uma Análise Exploratória de Dados completa, a empresa obteve insights valiosos sobre os fatores que influenciam as vendas, fornecendo uma base sólida para a tomada de decisões
- O projeto entregou com sucesso um Modelo de Previsão de Vendas, a fim de otimizar a alocação de recursos para renovações de lojas Rossmann
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn
- Análise Exploratória de Dados
- Robust Scaler, Min-Max Scaler, Label Encoder
- Linear Regression, Lasso Regression
- Random Forest Regressor, XGBoost, LightGBM
- MAE, MAPE, MSE, R²
- Cross-Validation
- Hyperparameter Tuning
Veja o projeto completo no GitHub: GitHub
Previsão de Destino de Táxis
Contexto de Negócio:
- Com as novas tecnologias, a indústria de táxis precisou se reinventar para não ficar para trás em relação aos seus novos concorrentes
- Um dos desafios é o novo sistema eletrônico de despacho em tempo real, o qual não define o destino final das corridas
- Em razão desse problema, a proposta é desenvolver um modelo preditivo que seja capaz de inferir o destino final de corridas de táxi com base em suas localizações de coleta
Objetivos:
- Entender o problema de negócio
- Análise dos dados das viagens
- Modelo de previsão de ponto de destino
- Apresentação descrevendo o problema e conclusões
Performances:
- O modelo final (LightGBM) performou bem e com resultados satisfatórios, com erros menores que 1 km
- Minimização de quilometragem vazia
- Maior satisfação do cliente
- Otimização de recursos
- Mais viagens em menos tempo
- Planejamento operacional
- Vantagem competitiva frente aos aplicativos
Ferramentas Utilizadas:
- Pandas, Numpy, Math, Matplotlib, Seaborn
- Folium
- Análise Exploratória de Dados
- LGBMRegressor
- Erro Absoluto Médio, Erro Médio Quadrático
- Pickle
- Hyperparameter Tuning com GridSearch CV
Veja o projeto completo no GitHub: GitHub
Projetos de Clusterização
Clusterização de clientes para campanha de marketing

Contexto de Negócio:
- O desafio central é aprimorar estratégias de negócios e marketing.
- Assim, realizando a clusterização dos clientes através do algoritmo K-Means, torna-se possível entender os comportamentos dos clientes e personalizar estratégias.
Objetivo Principal:
- Segmentar clientes em clusters distintos com o K-Means, entender seus comportamentos, preferências e aprimorar o direcionamento de estratégias para cada grupo.
Resultados alcançados:
- Insights sobre os clientes cadastrados e informações valiosas sobre os grupos de clusters.
- Estratégias de campanhas personalizadas para cada um, ajustes de produtos e preços de acordo com suas preferências e como abordar cada grupo de cliente.
- Cluster 0: Maior potencial; Cluster 1: Oportunidades de crescimento; Cluster 2: Alta rentabilidade; Cluster 3: Buscar engajamento
Benefícios:
- Os benefícios incluem estratégias de marketing mais eficazes, personalização de abordagens, melhor experiência para o cliente e otimização de recursos para potencializar o impacto nos negócios.
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn
- Normalização, Atribuição de Pesos
- Método de Elbow
- K-Means
Veja o projeto completo no GitHub: GitHub
Projetos de Sistemas de Recomendação
Além do "você também pode gostar de..."

Sobre a empresa:
- A Rex London, uma varejista de comércio eletrônico no Reino Unido, busca aumentar o engajamento e aprimorar a experiência do cliente
- O desafio é entender quais produtos são frequentemente comprados juntos, visando construir um sistema de recomendação personalizado
Objetivos:
- Realizar uma Análise Exploratória de Dados para entender padrões de comportamento
- Utilizar a Análise de Cesta de Mercado para identificar associações entre produtos
- Desenvolver um Sistema de Recomendação baseado na similaridade entre clientes
Resultados:
- A EDA revelou insights sobre as compras, produtos, comportamento temporal dos consumidores e a relação entre preço e quantidade
- A Análise de Cesta de Mercado identificou padrões de associação entre os produtos, classificando aqueles frequentemente comprados juntos, potencializando as vendas de produtos
- O Sistema de Recomendação gerou sugestões de produtos para clientes com base na sua similaridade com outros, maximizando a relevância das recomendações.
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn
- Análise Exploratória de Dados
- Apriori, Association Rules
- Cosine Similarity
Veja o projeto completo no GitHub: GitHub
Projetos Financeiros
Credit Scoring for Conservative Bank

Sobre Credit Score:
- Ferramenta crucial para instituições financeiras avaliarem seus clientes e a quantidade de dinheiro envolvida
- A análise engloba vários fatores, como renda anual, situação de propriedade de casa própria, valor do empréstimo e taxa de juros cobrada
Objetivo:
- Executar uma análise de pontuação de crédito para aumentar a rentabilidade de um banco conservador
- Realizar uma Análise Exploratória de Dados detalhada para entender melhor a base de dados e sua distribuição
Resultado:
- O resultado final é uma tabela com os clientes separados em decis
- Informações mais relevantes em cada divisão incluem quantidade de clientes envolvidos, quantos são bons, quantos são ruins, porcentagem de maus clientes evitada e o lucro que cada seleção de clientes proporciona
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn
- Análise Exploratória de Dados
- Encoders
- KNN Imputer
- RandomForestClassifier
- LightGBM, CatBoost
- Confusion Matrix, Classification Report, Accuracy Score, ROC Curve
Veja o projeto completo no GitHub: GitHub
Detecção de Fraudes

A importância da deteção de fraude:
- As repercussões da fraude vão além das perdas financeiras, incluindo danos à reputação, deterioração da confiança do cliente e possíveis ramificações legais
Objetivo:
- Construir um mecanismo de defesa para a instituição financeira fundamentado em técnicas de Ciência de Dados para fortalecer a infraestrutura de segurança e elevar a precisão dos processos de tomada de decisão
Resultado Final:
- O alto resultado de Recall dá confiança para seguir com esse modelo nas próximas etapas do projeto da instituição financeira, identificando uma fraude quando necessário
Ferramentas Utilizadas:
- Pandas, Numpy, Matplotlib, Seaborn, Graphviz
- Análise Exploratória de Dados
- SMOTE
- One-Hot Encoding, Label Encoder, Robust Scaler
- Logistic Regression, Decision Tree Classifier, Random Forest Classifier
- Confusion Matrix, Accuracy, Recall, Precision, F1 Score
- ROC Curve, ROC AUC Curve
- Hyperparameter Tuning, Randomized Search CV
Veja o projeto completo no GitHub: GitHub
📝 Projetos em Análise de Dados
Esse é um dos projetos que desenvolvi para aprimorar minhas habilidades de Análise de Dados. Respondo à perguntas de negócio através da exploração dos dados e com gráficos interativos da biblioteca Plotly.
Análise Exploratória para Olist

Contexto de Negócio:
- Olist é uma empresa de e-commerce no Brasil que oferece uma ampla gama de produtos em sua plataforma
- A empresa reconhece a importância de melhorar sua eficiência operacional e o primeiro passo para isso é entender mais sobre o comportamento de seus consumidores, variações nos pedidos, padrões de vendas por região, diferenças em preços e fretes por estado, satisfação dos clientes e mais
Objetivo:
- Criar uma Análise Exploratória de Dados (EDA) com os dados da empresa cobrindo diferentes áreas do negócio, como pedidos, produtos, consumidores, regiões, a fim de prover informação de qualidade para tomadas de decisão estratégicas
Conclusão:
- A análise proporcionou vários insights de negócio, como descrição de preços, características de pedidos, tendências temporais, preferências de pagamentos, padrões regionais e diários, relação entre tempo de entrega e avaliação do pedido, etc.
Ferramentas Utilizadas:
- Pandas, Numpy, Plotly Express
- Análise Exploratória de Dados
Veja o projeto completo no GitHub: GitHub
Sinta-se à vontade para entrar em contato comigo através de: